
Scientists have developed a new technique for turning audio clips into realistic video
Researchers generated realistic videos of the former US president talking with audio clips from a different interview.

Scientists have created new algorithms that turn audio clips into realistic lip-synced video.
Researchers at the University of Washington demonstrated their work by putting former President Barack Obama’s words into his own mouth, creating an almost-perfect audio-visual sync.
The hope is that the algorithms could be used to improve video conferencing or add visuals to an audio recording.
“When you watch Skype or Google Hangouts, often the connection is stuttery and low-resolution and really unpleasant, but often the audio is pretty good,” said Steven M Seitz, one of the study authors.
For years, scientists have tried to realistically match video to audio clips but have always hit a snag they call the “uncanny valley” problem – where a synthesised human voice appears to be almost real but misses the mark when matched up with the corresponding visuals, giving the video a creepy effect.
“People are particularly sensitive to any areas of your mouth that don’t look realistic,” said lead author Supasorn Suwajanakorn.
“If you don’t render teeth right or the chin moves at the wrong time, people can spot it right away and it’s going to look fake.
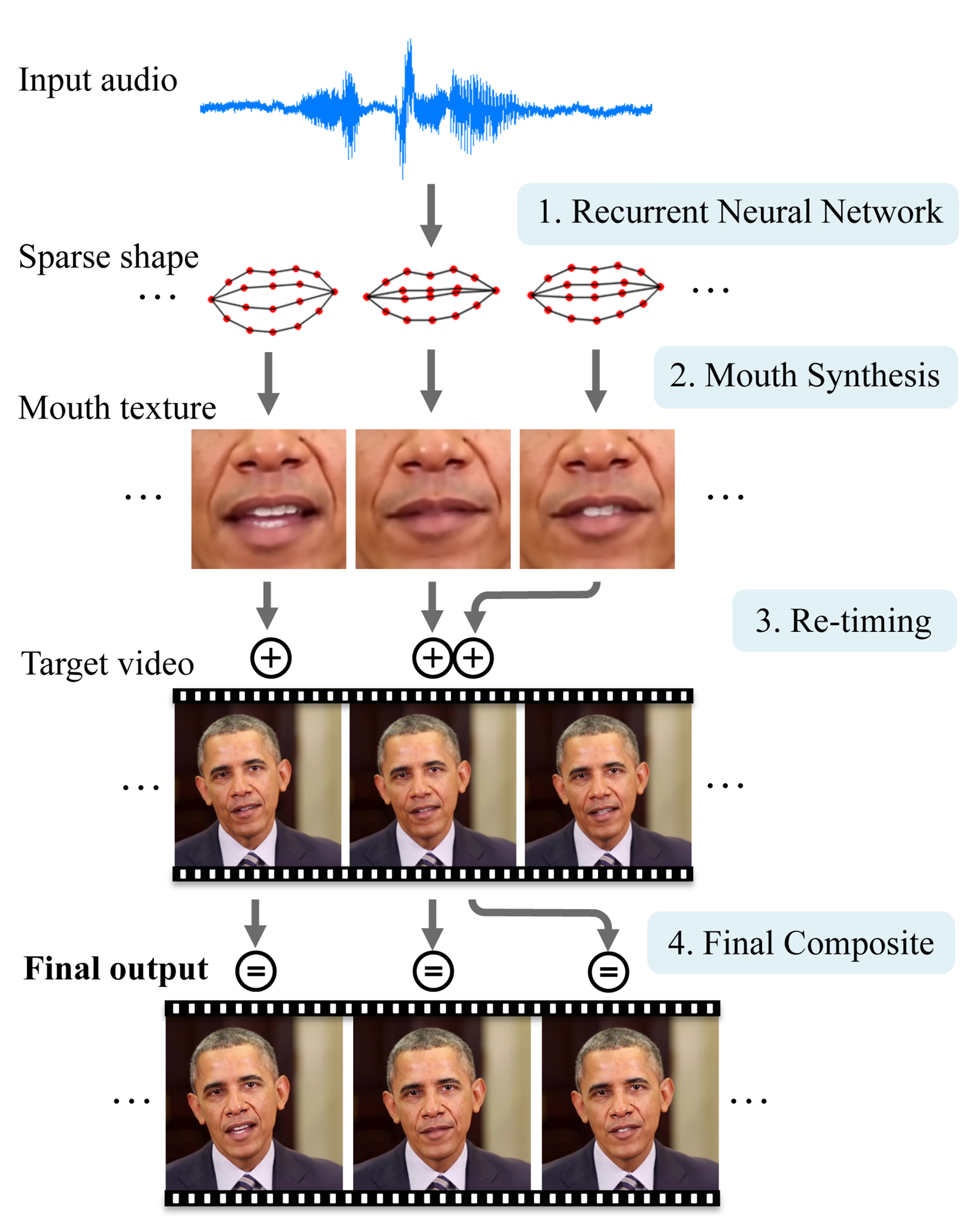
The researchers developed algorithms using videos that are widely available on the internet.
They then trained a neural network to watch the videos and translate the sound into basic mouth shapes.
The researchers also added a “small time shift” to allow it to anticipate what the speaker is going to say next.
While there are some occasional mistakes in mouth and facial alignment, the result looks very realistic.
But despite their success, the scientists don’t want to see misuse of this technology.
“You can’t just take anyone’s voice and turn it into an Obama video,” Seitz said.

“We’re simply taking real words that someone spoke and turning them into realistic video of that individual.”
According to the researchers, their algorithms could be developed to recognise a person’s voice and speech patterns using just an hour of video.
The results are being presented in August at SIGGRAPH 2017, a conference in computer graphics and interactive techniques.




